本文原创,可以转载, 但必须以超链接形式标明文章原始出处和作者信息
转载请注明: 转载自sin的专栏http://blog.csdn.net/yclzh0522
理解Sphere编程模型
为了介绍Sphere编程模型,举了下面一个例子。假如我们有来自Sloan Digital Sky Survey的天文图像集,目的是在这些图像里找出褐矮星(BrownDwarf)。SDSS数据集被存储成N个文件,命名为SDSS1.dat,……,SDSSn.dat,每个包含了至少一个图像。为了随机访问数据集里的一个图片,我们为每个文件建了一个记录索引。这些索引以.idx后缀命名:SDSS1.dat.idx,……,SDSSn.dat.idx。
为了使用Sphere,用户写了一个函数“findBrownDwarf”来从每个图像里查找褐矮星。在这个函数里,输入是一张图片和它的大小,输出是褐矮星在result里。
findBrownDwarf(char* image, int isize, char* result, int rsize);
一般的串行程序如下:
for each file F in (SDSS datasets)
for each image I in F
findBrownDwarf(I, …);
而如果使用Sphere客户端API的话,则代码如下:
SphereStream sdss, output;
sdss.init(“/sdss”);
SphereProcess* myproc = client.createSphereProcess();
myproc->run(sdss, "findBrownDwarf", output, parameter);
myproc->read(result);
在上面的代码里,“SDSS”是一个Sector流数据结构存储着SDSS文件的元数据。这个应用程序通过文件列表或者一个目录初始化流。Sphere自动获得来自Sector网络的元数据。用户把函数编译成动态库,并且用户用Sphere API来上传函数库到slave节点。这最后的三行启动这个job并且等待结果返回。不需要用户来移动数据,也不需要知道任何关于Sector系统信息(除了master节点可以连接的客户端位置)
在抽象层面,Sphere允许用户定义数据处理函数(UDF或者用户定义函数),接收一组Sector文件作为输入,并且能把结果写到一组Sector文件作为输出。我们用term Sphere流来描述Sector文件组,可做输入或者输出。
Inputs -> UDF -> Outputs
在上图中,输入和输出可以是单个或者多个流,同时一个Sphere的处理输出可以作为下一个处理的输入。一个Sphere流被切分成多个数据片段并且被slave的SPE(Sphere Processing Engines)处理。一个SPE处理每个数据片段可以是一个数据记录,或者一组记录甚至一个完整的物理文件。Sphere Stream,files,data segments,data elements和SPE关系如下图1所示:
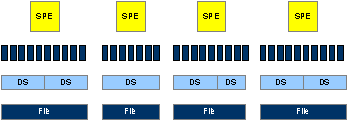
为了切分流,一个包含了每个记录大小和位置索引文件被用户定义和存储在Sector里。如果没有索引文件存在,这个最小数据片段等于一个文件。对于文本文件,一个索引可以自动产生作为一行一条记录。
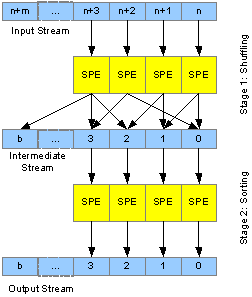 Figure 2. Data flow of a sorting process
Figure 2. Data flow of a sorting process
每个数据片段的输出可以送回客户端,写到本地磁盘,也可以根据用户定义的hash函数送到多个目的地。图2显示一个用Sphere的排序处理。在开始阶段,每个SPE读入一个来着本地的片段,处理每条记录,根据key送到适合的目的地。第一阶段的输出时中间流。在第二阶段,每个SPE在流里对本地文件排序。在第二阶段没有数据移动。
本文原创,可以转载, 但必须以超链接形式标明文章原始出处和作者信息
转载请注明: 转载自sin的专栏http://blog.csdn.net/yclzh0522
分享到:




相关推荐
一个C++版本的mapreduce实现。
sphere测试函数,matlab平台进行实验
fusionsphere openstack 云数据中心搭建36计-04.mp4,网盘文件,永久链接 fusionsphere openstack 云数据中心搭建36计-05.mp4 fusionsphere openstack 云数据中心搭建36计-06.mp4 fusionsphere openstack 云数据中心...
2.2_OpenStack之于虚拟化(2017.5.30) 2.3_OpenStack之于云计算(2017.5.30) 2.4_OpenStack发展历程(2017.5.30) 2.5_OpenStack的设计准则(2017.5.30) 2.6_OpenStack的架构(2017.5.30) 3.1_FusionSphere概述(2017....
UO的51a服务器端有下的速度了
Photo-Sphere-Viewer,及使用过程中的使用案例及注意点
SphereFace论文人脸识别SphereFace论文人脸识别SphereFace论文人脸识别
华为fusionsphere
基本粒子群优化算法,: Sphere测试函数
资源来自pypi官网。 资源全名:s2sphere-0.2.5.tar.gz
Fusionsphere6.5.1全套
华为FusionSphere 5.0 特性描述
vmware sphere 5简易教程,官网下载,虚拟机
Mi Sphere Camera Teardown
sphereface的pytorch实现代码,2017的一篇cvpr,SphereFace: Deep Hypersphere Embedding for Face Recognition,继centerloss之后又一大作。 文章主要提出了归一化权值(normalize weights and zero biases)和...
FusionSphere 虚拟化套件 8.0.0 产品文档 06.zip
插件描述:Photo Sphere Viewer是一款基于Three.js的360X180度全景图预览js插件。演示地址:http://www.jq22.com/jquery-info10782
华为云计算解决方案产品 水平:FusionSphere/云操作系统 垂直:FusionCube/融合一体机 接入:FusionAccess/桌面云 融合致简、深度优化 安全、高效、卓越体验 FusionCloud 最优性价比 数据:FusionInsight/大数据...
Sphere5管理员手册PDF档
FusionSphere Foundation版下载